搜索到
29
篇与
AI
的结果
-
 Spark-TTS,极简版音频克隆 Spark-TTS,极简版音频克隆 干啥的? 如果你是播客,经常在b站发视频解说之类的 可以录制一段你说话的录音 然后输入一段文本,生成音频,用你的音色生成一段音频 你还可以叫猪八戒给你讲故事 等等等等 使用方法非常简单 上传一段参考音频或者录制你自己的声音 输入你想转换成音频的文本 点击开始克隆即可 Spark-TTS是一款先进的文本转语音(Text-to-Speech,TTS)系统, 它利用大型语言模型(Large Language Model,LLM)的强大功能,实现了高度准确且自然流畅的语音合成。 该系统旨在为研究和生产使用提供高效、灵活且强大的解决方案。 Spark-TTS的核心优势在于其简洁性和效率。 它完全基于Qwen2.5构建,无需额外的生成模型,如流匹配模型等。 这一设计使得Spark-TTS能够直接从LLM预测的代码中重构音频,从而简化了流程,提高了效率,并降低了复杂性。 这种创新的方法使得Spark-TTS在语音合成领域具有显著的优势。 此外,Spark-TTS还支持零样本语音克隆(Zero-Shot Voice Cloning), 这意味着它可以复制说话者的声音,而无需为该声音提供特定的训练数据。 这一功能在跨语言和代码切换场景中尤为有用,它允许Spark-TTS在不同的语言和声音之间无缝切换,而无需为每个语言或声音分别进行训练。 Spark-TTS还支持中文和英文,这使得它能够在多种语言环境中提供高质量的语音合成服务。 同时,通过调整参数如性别、音调和语速等,Spark-TTS还可以创建虚拟说话者,为用户提供更加个性化的语音合成体验。 然而,需要注意的是,Spark-TTS主要用于学术研究、教育目的以及合法应用,如个性化语音合成、辅助技术和语言学研究等。 用户在使用时应遵守当地法律法规和道德规范,不得将Spark-TTS用于未经授权的语音克隆、冒充、欺诈、诈骗、深度伪造或任何非法活动。 jian27打包 [https://www.jian27.com/html/1459.html](https://www.jian27.com/html/1459.html) 我在jian27打包基础上进行了二次负优化 将我不需要的web界面进行了删减 删减了原包中用不上的文件,压缩包整体进行了减肥(原作 5.99gb,本站负优化后,4.11gb) 修复了一个致命bug 当文本输入框中有回车换行时,原作只会生成第一句,剩下的都舍弃了 本站所发的版本已经修复该问题,回车也不影响音频生成 另外还加了显存回收 效果的话,大概能达到原音参考音频的7成左右 某些时候转换出来的音频会语速较快 需要黄皮显卡,显存4gb以上即可 推荐6gb以上显卡 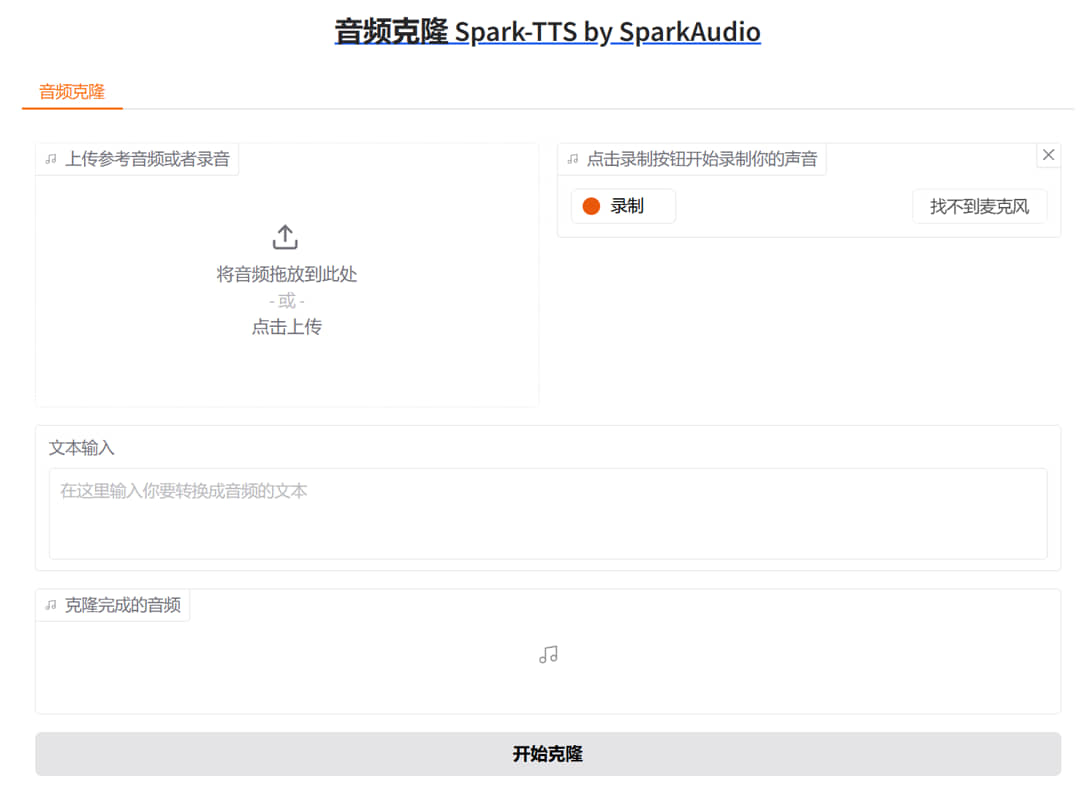 回复后,刷新可以看见下载链接 隐藏内容,请前往内页查看详情
Spark-TTS,极简版音频克隆 Spark-TTS,极简版音频克隆 干啥的? 如果你是播客,经常在b站发视频解说之类的 可以录制一段你说话的录音 然后输入一段文本,生成音频,用你的音色生成一段音频 你还可以叫猪八戒给你讲故事 等等等等 使用方法非常简单 上传一段参考音频或者录制你自己的声音 输入你想转换成音频的文本 点击开始克隆即可 Spark-TTS是一款先进的文本转语音(Text-to-Speech,TTS)系统, 它利用大型语言模型(Large Language Model,LLM)的强大功能,实现了高度准确且自然流畅的语音合成。 该系统旨在为研究和生产使用提供高效、灵活且强大的解决方案。 Spark-TTS的核心优势在于其简洁性和效率。 它完全基于Qwen2.5构建,无需额外的生成模型,如流匹配模型等。 这一设计使得Spark-TTS能够直接从LLM预测的代码中重构音频,从而简化了流程,提高了效率,并降低了复杂性。 这种创新的方法使得Spark-TTS在语音合成领域具有显著的优势。 此外,Spark-TTS还支持零样本语音克隆(Zero-Shot Voice Cloning), 这意味着它可以复制说话者的声音,而无需为该声音提供特定的训练数据。 这一功能在跨语言和代码切换场景中尤为有用,它允许Spark-TTS在不同的语言和声音之间无缝切换,而无需为每个语言或声音分别进行训练。 Spark-TTS还支持中文和英文,这使得它能够在多种语言环境中提供高质量的语音合成服务。 同时,通过调整参数如性别、音调和语速等,Spark-TTS还可以创建虚拟说话者,为用户提供更加个性化的语音合成体验。 然而,需要注意的是,Spark-TTS主要用于学术研究、教育目的以及合法应用,如个性化语音合成、辅助技术和语言学研究等。 用户在使用时应遵守当地法律法规和道德规范,不得将Spark-TTS用于未经授权的语音克隆、冒充、欺诈、诈骗、深度伪造或任何非法活动。 jian27打包 [https://www.jian27.com/html/1459.html](https://www.jian27.com/html/1459.html) 我在jian27打包基础上进行了二次负优化 将我不需要的web界面进行了删减 删减了原包中用不上的文件,压缩包整体进行了减肥(原作 5.99gb,本站负优化后,4.11gb) 修复了一个致命bug 当文本输入框中有回车换行时,原作只会生成第一句,剩下的都舍弃了 本站所发的版本已经修复该问题,回车也不影响音频生成 另外还加了显存回收 效果的话,大概能达到原音参考音频的7成左右 某些时候转换出来的音频会语速较快 需要黄皮显卡,显存4gb以上即可 推荐6gb以上显卡  回复后,刷新可以看见下载链接 隐藏内容,请前往内页查看详情 -
FunASR-webui,音频转成文本 FunASR-webui 用于将音频转成文本 例如会议录音转成文字记录 mp4视频文件转换成字幕文件等等 运行界面如下 加载音频或者MP4文件 点击开始按钮 耗时视音频长度而不一 效率还是很高的 转换完成会在out目录自动保存为三个格式 一个txt,一个视频字幕文件,一个音频歌词格式文件 消耗显存约2.5gb左右 转载于 B站十字鱼 [https://www.bilibili.com/video/BV193AfenEiv/?spm_id_from=333.1387.homepage.video_card.click](https://www.bilibili.com/video/BV193AfenEiv/?spm_id_from=333.1387.homepage.video_card.click) 作者的开源页面 [https://github.com/gluttony-10/FunASR-webui](https://github.com/gluttony-10/FunASR-webui) 本站独家负优化 显著减少体积,压缩包3.2gb(原作5.4gb) web界面简化 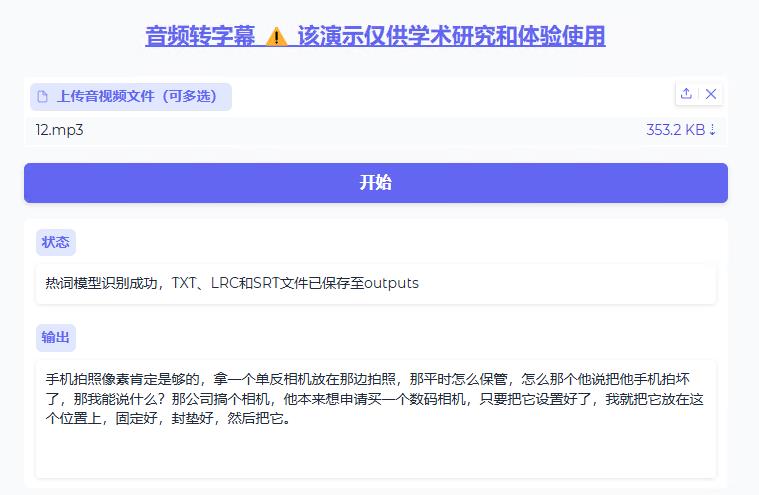 百度网盘下载链接,回复后刷新可见 隐藏内容,请前往内页查看详情
-
Sonic,一键包,数字人工具,音频驱动图片说话,腾讯联合浙大开源 Sonic,一键包,数字人工具,音频驱动图片说话,腾讯联合浙大开源 用人话介绍: 给一张图片,给一段音频,然后他会根据音频内容让图片转成视频并配合音频调整嘴型以及面部生态 [转载自B站十字鱼](https://www.bilibili.com/video/BV1bjFLe7EZd/?spm_id_from=333.1387.homepage.video_card.click&vd_source=593137df0281be7bde42cb018cfaedab) 官方项目地址 [https://github.com/jixiaozhong/Sonic](https://github.com/jixiaozhong/Sonic) 本站负优化 首先减肥2gb 汉化界面 删除了页面多余的示例 优化了文件目录,看起来更清爽 增加了显存回收 效果图 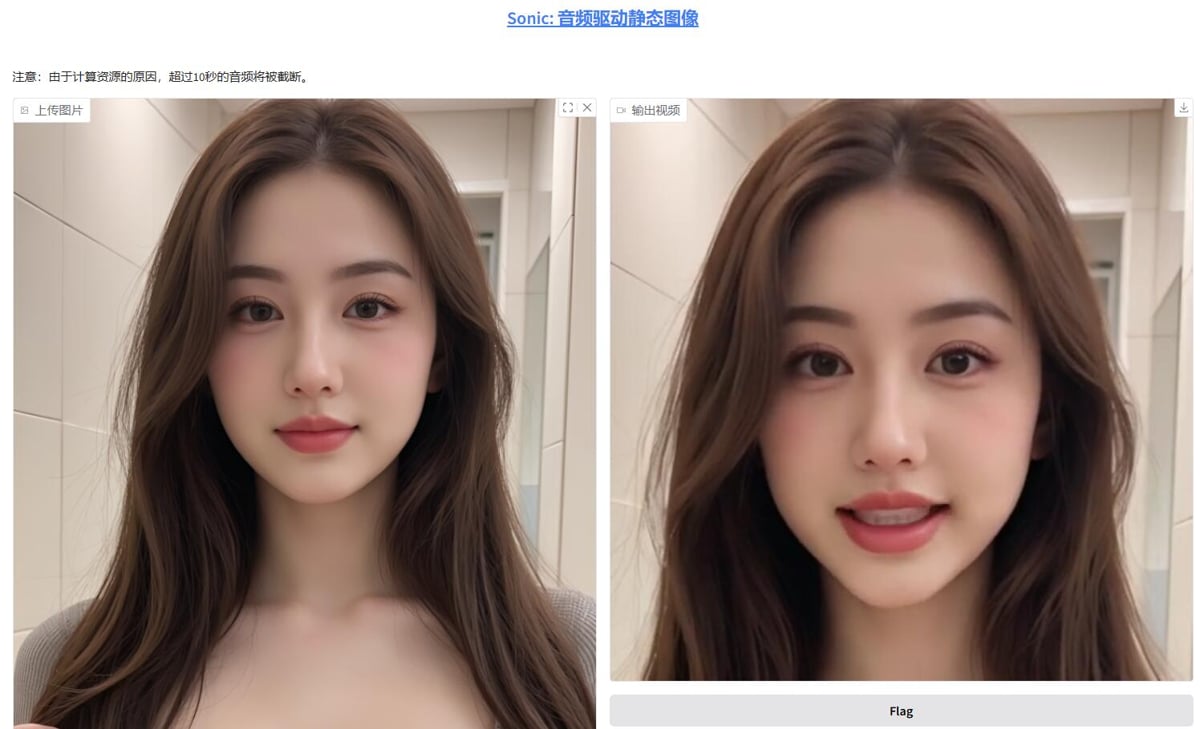 完整界面 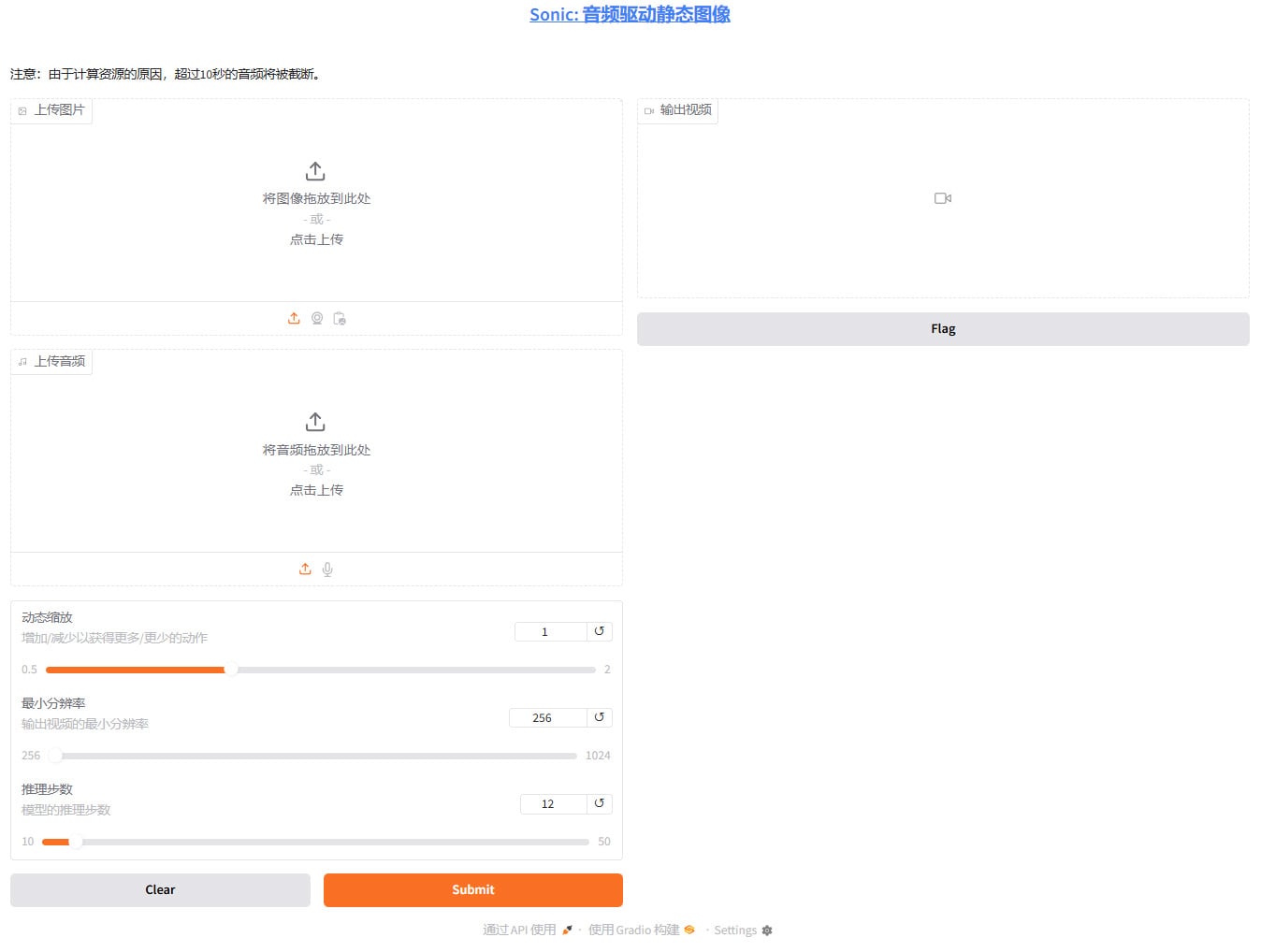 链接: [https://pan.baidu.com/s/1G1Hl3DFqJq8ObnA2ujNRbQ?pwd=gpcb](https://pan.baidu.com/s/1G1Hl3DFqJq8ObnA2ujNRbQ?pwd=gpcb)
-
什么是人工智能(AI) 什么是人工智能(AI)  李开复老师用通俗的语言来解释,人工智能、机器学习、神经网络、深度学习……这些词到底是什么意思?彼此有什么关系? 我觉得,这些介绍对理解 AI 的体系,挺有启发的。它们分散在各个章节,我将它们整理在一起。 为了行文连贯,我没有完全照搬原文,而是用自己的语言重新叙述,如果有错误,也归咎我。 (1)人工智能 1956年夏天,计算机科学家约翰·麦卡锡(John McCarthy)首次提出“人工智能”(AI)这个概念。 人工智能指的是,通过软件和硬件,来完成通常需要人类智能才能完成的任务。它的研究对象,就是在机器上模拟人类智能。 (2)机器学习 早期,人工智能研究分成两个阵营。 第一个阵营是规则式(rule-based)方法,又称专家系统(expert systems),指的是人类写好一系列逻辑规则,来教导计算机如何思考。 可想而知,对于复杂的、大规模的现实问题,很难写出完备的、明确的规则。所以,这种方法的进展一直很有限。 第二个阵营就是机器学习(machine learning),指的是没有预置的规则,只是把材料提供给计算机,让机器通过自我学习,自己发现规则,给出结果。 (3)神经网络 神经网络(neural network)是机器学习的一种主要形式。 神经网络就是在机器上模拟人脑的结构,构建类似生物神经元的计算网络来处理信息。 一个计算节点就是一个神经元,大量的计算节点组成网络,进行协同计算。 神经网络需要极大的算力,以及海量的训练材料。以前,这是难以做到的,所以20世纪70年代开始,就陷入了停滞,长期没有进展。 (4)深度学习 深度学习是神经网络的一种实现方法,在20世纪80年代由杰弗里·辛顿提出。它让神经网络研究重新复活。 深度学习是一种让多层神经元可以进行有效计算的方法,大大提高了神经网络的性能。“深度学习”这个名字,就是比喻多层神经元的自主学习过程。 多层神经元包括一个输入层和一个输出层,它们之间有很多中间层(又称隐藏层)。以前,计算机算力有限,只能支撑一两个中间层,深度学习使得我们可以构建成千上万个中间层的网络,具有极大的“深度”。 (5)Transformer 早些年,深度学习用到的方法是卷积神经网络(CNN)和循环神经网络(RNN)。 2017年,谷歌的研究人员发明了一种新的深度学习处理方法,叫做 Transformer(转换器)。 Transformer 不同于以前的方法,不再一个个处理输入的单词,而是一次性处理整个输入,对每个词分配不同的权重。 这种方法直接导致了2022年 ChatGPT 和后来无数生成式 AI 模型的诞生,是神经网络和深度学习目前的主流方法。 由于基于 Transformer 的模型需要一次性处理整个输入,所以都有“上下文大小”这个指标,指的是一次可以处理的最大输入。 比如,GPT-4 Turbo 的上下文是 128k 个 Token,相当于一次性读取超过300页的文本。上下文越大,模型能够考虑的信息就越多,生成的回答也就越相关和连贯,相应地,所需要的算力也就越多。 [本文转载 ](https://github.com/ruanyf/weekly/blob/master/docs/issue-330.md)
-
Clarity-Refiners-UI,图像增强,懒人包 用于图像增强,可以理解为将模糊的图片变清晰 将图像重绘放大超分 jian27打包 [https://www.jian27.com/html/2619.html](https://www.jian27.com/html/2619.html) Pinokiofactory/Clarity-Refiners-UI 是一个专注于图像增强的开源项目,它基于 Pinokio UI 框架,并融合了多项先进的图像处理技术。 该项目旨在为用户提供一种高效、易用且功能强大的图像增强解决方案。 项目背景与目的 它起源于对图像清晰度和细节提升的追求。 通过整合和优化现有的图像处理算法,该项目旨在为用户提供一个能够轻松实现图像质量飞跃的平台。 无论是专业摄影师、设计师还是普通用户,都能通过这款工具轻松提升图像的视觉效果。 可以单张超分,也可以批量操作 6gb显卡即可畅玩 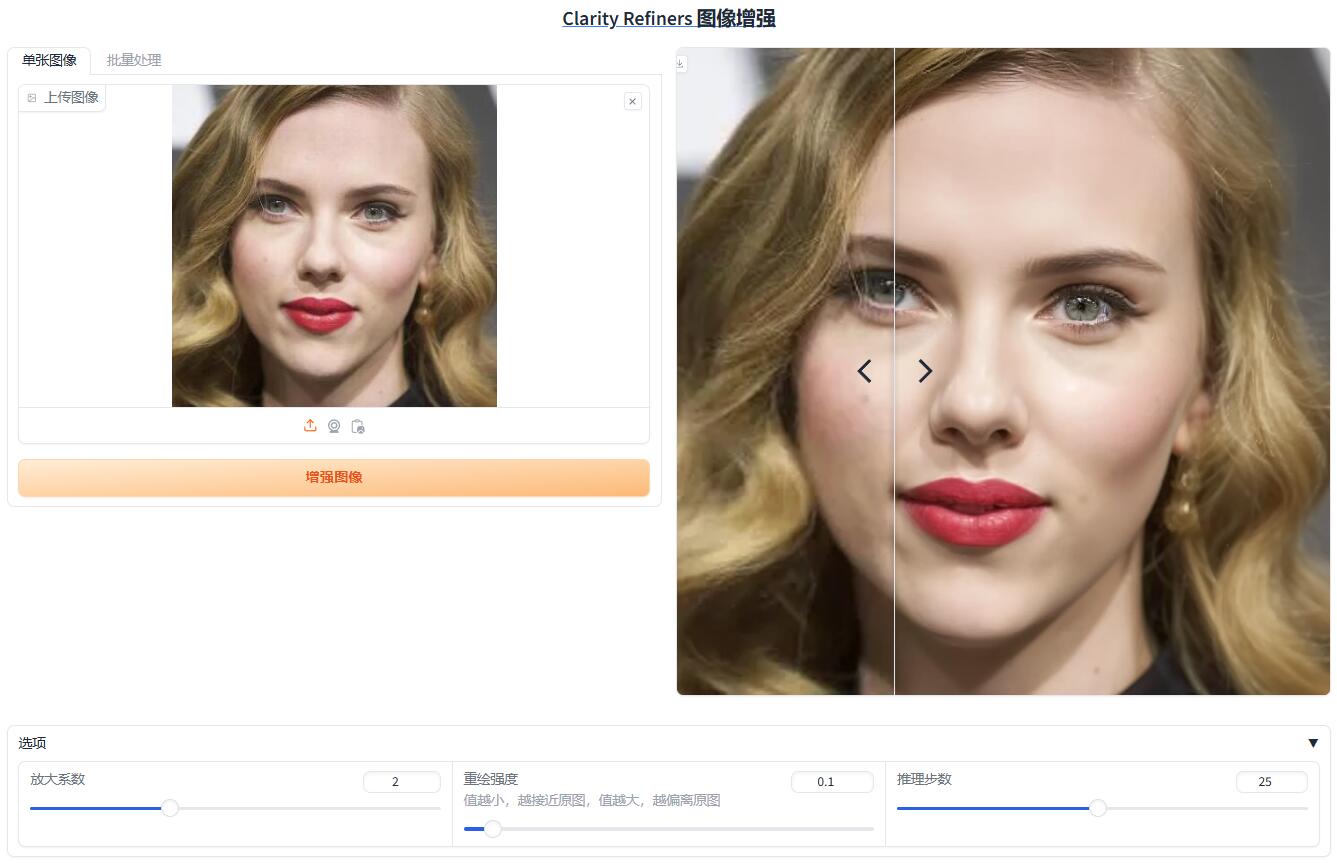 本站负优化内容 简化软件目录 简化web软件界面 简化软件包体积 懒人包打包上传中 下载链接回复后刷新可见 隐藏内容,请前往内页查看详情
-
Diffusers-Image-Community,AI扩图,新版懒人包 AI扩图的 使用非常简单,已经将原界面尽量简化了 就不做过多介绍了 实在不懂,自己去看原作者刘锐视频讲解 我有B站账号,但是转正还得做很多题 还是免了 转载自刘锐博客 [https://www.bilibili.com/video/BV1QgSKYPEim/?spm_id_from=333.999.0.0](https://www.bilibili.com/video/BV1QgSKYPEim/?spm_id_from=333.999.0.0) 项目地址: [https://github.com/ai-anchorite/Diffusers-Image-Community](https://github.com/ai-anchorite/Diffusers-Image-Community) 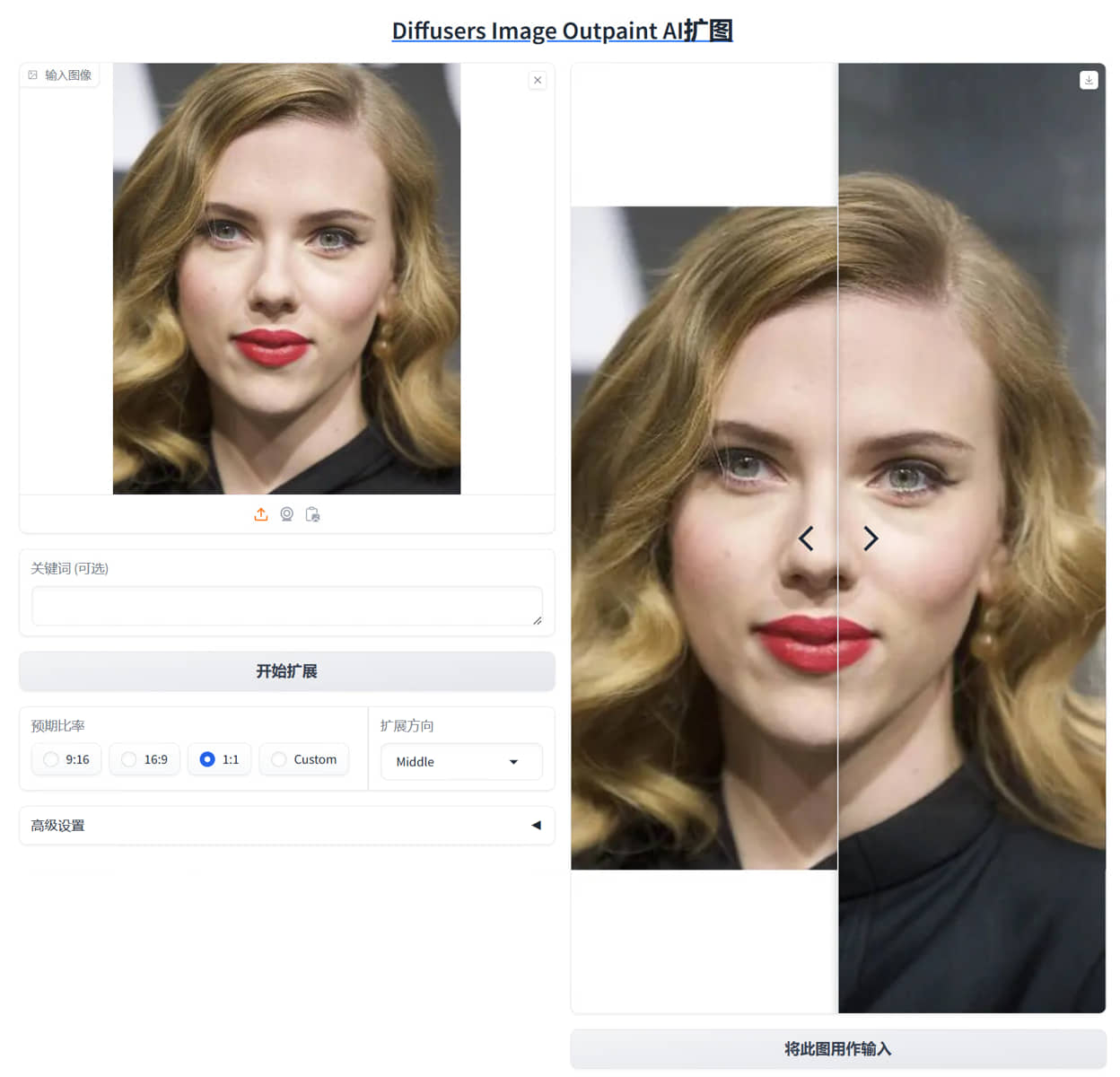   本站独家负优化 首先减肥了 原版18.4gb,本站删除了3gb,现在只有15.4gb 粗略汉化了界面 界面做了删减 内存显卡都建议16gb起 显卡8gb可以用,稍慢点 实测显存占用14.5gb PS:回宿舍测试发现代码有些问题 例如我默认设置的是1:1,实际是9:16 用生成的图做原图似乎也有些问题 但是我不想再改了 因为宿舍断网了 不影响使用 也就玩完,没什么大碍 隐藏内容,请前往内页查看详情
-
OmniGen,AI文生图,图生图,身份保留,懒人包 OmniGen,AI文生图,图生图,身份保留,懒人包 干啥的? 你可以上传一到三张参考图片 根据参考图片进行融合 你可以上传一张照片,叫模型给你加上一副眼镜,同时照片身份会被保留 你可以直接写提示词,让模型给你画图 更多用法还需要你自己琢磨 转载自刘悦的技术博客 [https://www.bilibili.com/video/BV1BAS9Y5EHk/?spm_id_from=333.999.0.0](https://www.bilibili.com/video/BV1BAS9Y5EHk/?spm_id_from=333.999.0.0) 刘悦的技术博客 [https://github.com/v3ucn](https://github.com/v3ucn) 本项目开源,开源地址 [https://github.com/Manni1000/OmniGen](https://github.com/Manni1000/OmniGen) 本项目带有低显存模式,只需要6gb显存即可出图 默认勾选低显存模式,4060 8gb 占用6gb显存,1024分辨率出图大约75秒一张 本站负优化内容: 优化了目录结构 优化了web界面 上传图片即自动加上 img>